IT業界の行動をアップデート
V-JOURNAL
【GPTとは】ChatGPTのGPTの仕組みと歴史、活用方法を徹底解説!
2023/06/10
ここ最近で、大規模言語AIサービス「ChatGPT」という言葉を耳にする方が増えたのではないでしょうか?
今や、IT業界だけでなく、各種メディアが取りあげChatGPTの認知度が上がってきています。
ChatGPTとは、米国のOpenAI社(以下、OpenAI)が「GPT」という自然言語処理技術を応用し開発した「AIチャットサービス」のことです。
実はこの「GPT」が一言でいうとすごい!ChatGPTだけでなく、近年のAI開発で使われている技術となっています。
本記事では、ChatGPTを構成するGPTとは何か?GPTの仕組みと歴史、活用方法を詳しく説明します。
目次● GPTとは?● GPTの仕組み▶️ GPTのベース┗・Transformerとは┗・Attention(層)とは● GPTの学習方法● GPTの歴史● GPTの活用方法▶️ カスタマーサポート▶️ 予約業務▶️ 企業データの分析▶️ マーケティング● まとめ● VNEXTはGPTに関する開発にも対応● おすすめのAI資料 |
|GPTとは?
GPTとは「Generative Pre-trained Transformer」の略であり、OpenAIが開発した大規模言語モデルを指します。
簡単に説明すると、
AIが大量のテキストデータを学習し、文章の生成や言語理解の能力を身につけ、次の予測や推測ができるようになった"次世代型言語モデル"です。
ChatGPTも同様に2018年にOpenAIが開発し、AIが自動でチャットに対応するサービスとなっています。
GPTを活用したクオリティの高い言語作成や文章作成が可能で、機能は単語や文法からフィードバックにより常に学習し文章を作成してくれるので、
チャットをする際にも、より簡潔な会話やメッセージの生成を可能としています。
|GPTの仕組み
GPT の仕組みは、各単語が他の単語とどのように関連しているかを計算し、その関連度に基づいて情報を集約します。
そして、膨大な量のテキストデータを自動で学習することで文章生成や言語理解などを行う構造となっています。
▶️ GPTのベース
GPTの仕組みを語る上で、GPTのベースとなっている「Transformer」の説明は欠かせません。
ここは、GPT(Generative Pre-trained Transformer)の「Transformer」の部分にあたります。
今回は、このTransformerについて簡単・簡潔に説明しますので、「Transformerってすごいな」程度にご理解いただければ大丈夫です。
・Transformerとは
Transformerは、2017年に発表された"Attention Is All You Need"という自然言語処理に関する論文の中に登場したニューラルネットワークモデル*です。
*ニューラルネットワークモデル:人間の脳の構造と働きをモデルにしたAIのこと
Transformerは一言でいうと「処理が速い、精度も高い、汎用性も高くて何にでも使える」、昨今のAI進化のベースになっているモデルのことです。
汎用性が高いことから、GPTやBERT*など数多くの最先端モデルに使用されています(頭脳明晰、運動神経抜群、性格良しの人気者みたいなイメージ)
*BERT:Google AIが開発した自然言語処理(NLP)の事前学習済み言語モデル
なぜ、そんなに人気者なのかというと、従来モデル(RNN*)が抱えていた以下の課題をサクッと解決したからです。
*RNN(Recurrent Neural Network):ここでは"ニューラルネットワークの一種"とだけ把握してください
<従来モデルの課題>
・長期記憶が苦手
・並列処理(同時に複数のタスクを処理する)ができない
・学習スピードがおそい
・大規模データを使用できない
従来モデルでは、単語を1つ1つ処理していくので時間がかかっていましたが、
Transformerでは「同時に複数のタスクを処理する(並列処理)ことが可能」です。
従来モデルとTransformerの処理を比較したものが以下の図となります。
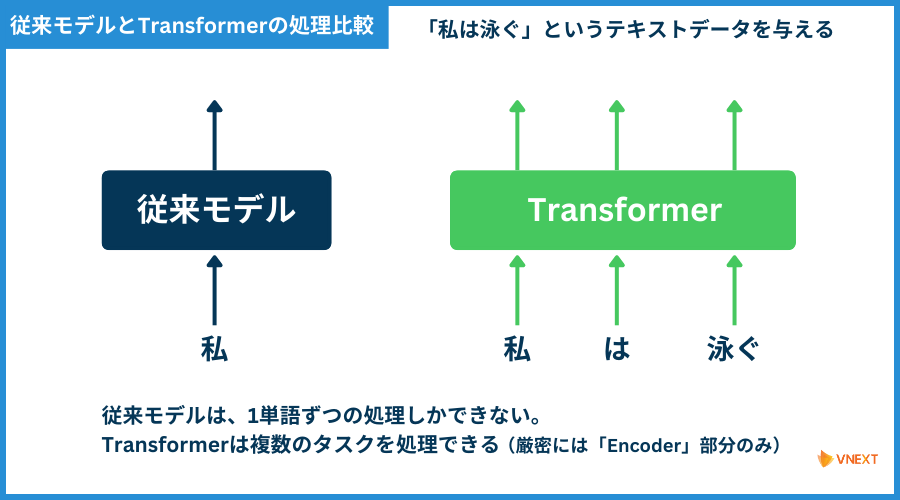
上記の図に「Encoder」という単語が出てきました。
タスクの処理では、EncoderとDecoderという2つのブロックを作り、作業を分担しています。
これは以下の図のように、「一度処理しやすい形にしてから、メインの処理をする」という仕組みです。
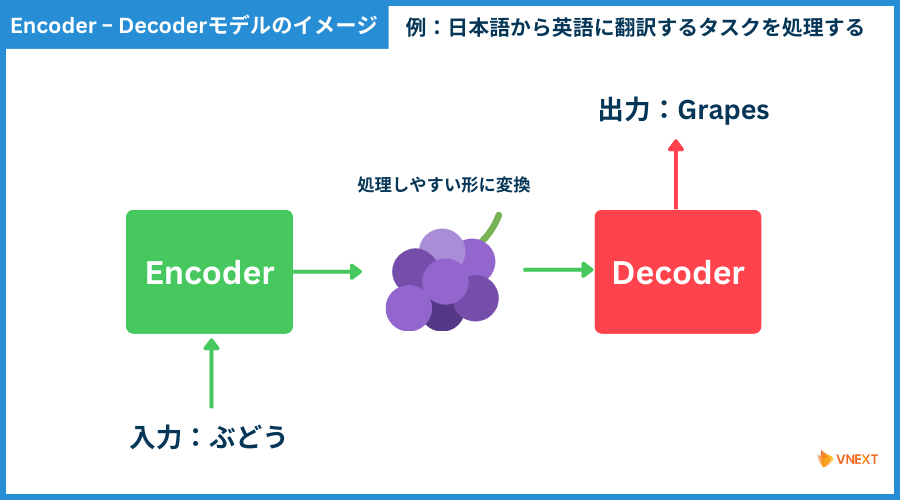
この「Encoder」部分がTransformerだと並列処理ができるのです。("私は泳ぐの図"をイメージしてください)
Transformerがこのように高スペックになったのは「Attention」という層だけを使う、画期的な仕組みにしたからです。
(上述の"Attention Is All You Need"がここにつながります)
・Attention(層)とは
Attentionとは大雑把に言うと、AIに「そのタスクには、どの単語が重要か、注目(Attention)すべきか」を教える仕組みのことです。
たとえば、以下のような文があったとします。
|リリーはとてもお腹が減ったので、お母さんに「()!」と言った
()の中にどのような文章が入るかほとんどの人が分かると思います。
おそらく
|リリーはとてもお腹が減ったので、お母さんに「何か食べたい!」と言った
でしょう。
このようにテキストの文脈からワードを推論するためには、周りの文脈が非常に重要となります。
上記のような短い文であれば従来の手法(RNN)でも十分でした。
しかし、上記の文が以下のように長い文になった場合はどうでしょうか?
リリーは朝から夕方までバスケットボールをしていた。
昼ごはんを食べ忘れるほど夢中になって、遊んだ後はそのまま帰宅した。
リリーはとてもお腹が減ったので、お母さんに「()!」と言った。
リリーはお母さんに「何か食べたい!」というまでに、いろんなことが起こっています。
そのため、文脈を読み取るのが難しくなっています。
そこで、Attentionの登場です!「この文脈ではこの部分が重要だ」とAIに理解させることができます。
従来の手法とAttentionの比較をしたものが以下の図です。
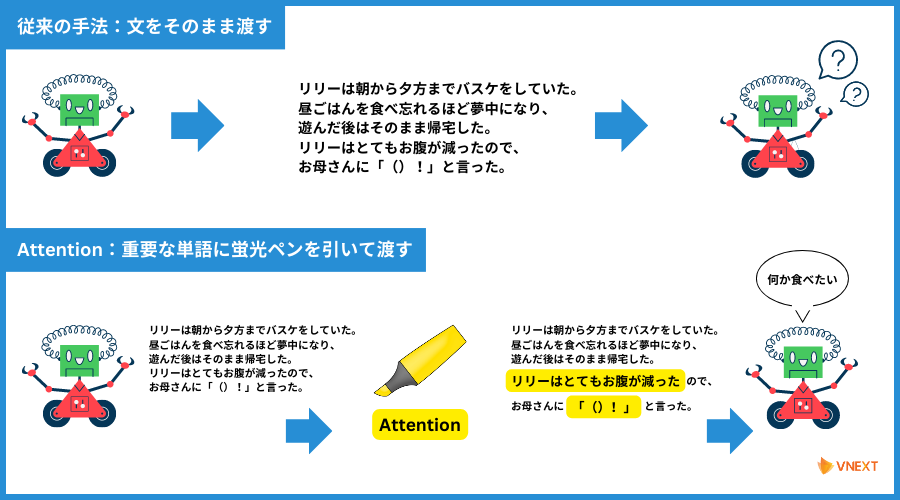
従来モデルは課題点を「Attentionでサポート(RNN & Attention)」していましたが、Transformerはこの「Attentionの仕組みだけを使う」ことで、
"長期記憶ができない" や "学習スピードが遅い"などの問題点を解決したのです。
|GPTの学習方法
上述では、GPTのベースについて説明をしました。それを踏まえて、GPTの学習方法を解説していきます。
GPTの学習方法は、以下の2つのステップで構成されています。
ステップ1:事前学習(pre-training)
ステップ2:ファインチューニング(fine-tuning)
▶️ ステップ1:事前学習(pre-training)
このステップは、GPT(Generative Pre-trained Transformer)の「Pre-trained」部分です!
事前学習の目的は、「GPTモデルが自然言語のパターンや文法を学び、文章の文脈や意味を理解する」ことです。
これにより、GPTモデルは文章生成や文章補完などのタスクで優れたパフォーマンスを発揮する「準備」をします。
具体的な手順としては、以下のような流れで事前学習が行われます。
① テキストデータのトークン化
収集したテキストデータを小さな単位(トークン)に分割します。通常、単語単位やサブワード(部分的な単語)単位でトークン化されます。
② モデルの構築
GPTモデルは、複数に積み重なったTransformer層から構成されます。
各層にはMulti-head Attention層*があり、文脈の依存関係を捉えるために使用されます。
*Multi-head Attention:Attentionよりも複数箇所の重要な部分に注目することができ、文脈の理解をより向上させるAttentionの進化版みたいなもの
③ 入力データの生成
トークン化されたテキストデータを入力し、GPTモデルによって次のトークン(単語や文字)を予測するように訓練します。
④ 学習の反復
大量のトークンを使用して、モデルの学習を複数の反復(エポック)で行います。
モデルは、与えられた文脈から正しい次のトークンを予測することで、文法や文脈のパターンを把握していきます。
⑤ パラメータの最適化
学習中には、予測と実際の次のトークンの間の差異を測定する損失関数が使用されます。
この損失を最小化するために、モデルのパラメータ*が最適化されます。
*パラメータ:モデルの特徴や性質を表すために使用される数値や変数のことで、モデルの振る舞いや動作を制御する役割を持っています
事前学習では、主に"Transformerの構造"と"Attentionの仕組み"が使用されています。
Transformerの層とMulti-head Attentionを組み合わせることで、GPTモデルは文脈の依存関係を捉えることができます。
▶️ ステップ2:ファインチューニング(fine-tuning)
ファインチューニングは、GPTモデルを特定のタスク(文章生成や質疑応答など)に適用するために、
「事前学習済みのモデルを追加のタスク固有データで学習させる」プロセスです。
タスク固有データとは、特定のタスクに関連するデータセットのことを指します。タスク固有データは、GPTモデルを特定の目的や用途に適用するために使用されます。
たとえば、「感情分析のタスク」を考えてみましょう。
タスク固有データはテキストデータとそのテキストに対する感情ラベル(例として「ポジティブ」や「ネガティブ」)の組み合わせです。
このデータを使用してモデルをトレーニングすることで、新しいテキストの感情を予測することができます。
このように、ファインチューニングによって、モデルは特定のタスクに適応した表現や特徴を獲得し、高いパフォーマンスを発揮するようになります。
記事の序盤にある「GPTとは?」の説明で、”次世代型言語モデル”と表現しましたが、従来と何が違うのか?それがこの"学習方法"です!
一般的に、AIの機械学習では「教師データ(入力データと正解)」を大量に用意して"教師あり学習"をさせていきます。
教師データは、データが十分且つ多様であればあるほど、モデルは様々なパターンや変動性を学習し、より正確で一般的な予測を行うことができます。
このように「教師データ」は用意する(作る)こと自体がとても大変な作業で、AI開発をする工程で1番時間がかかる部分となります。
GPTでは「事前学習」で"教師なし学習"をした後に、特定のタスクに合わせて「ファインチューニング」することで大規模データの学習を可能にしたのです。
「ファインチューニング」部分が "教師あり学習" になるので、GPTの学習方法は "半教師あり学習" と呼ばれることもあります。
なぜ、「事前学習」は "教師なし学習" となるのでしょうか?
たとえば、英語を日本語に変換するタスクの場合
| Grapes > ぶどう
このような、特定の入力に対して出力のラベル(正解)付けをした教師データを用意する必要があります。
しかし、事前学習段階のテキストデータは、
| 私はぶどうが好き
のような文章を入れて、単語を分割した後に、それぞれの単語を一時的に隠す・欠損させ(これをマスクといいます)
| 私/は/ぶどう/が/()
上記のように()部分の予測を促すなどを行い、学習してくれるので人間がラベル付けをする必要がなく、大量のテキストデータを与えてあげるだけでいいのです。
それゆえに、"教師なし学習" と言われています。
このように、最初から「教師データ」を用意せずに学習させることが画期的であり「GPTがすごい」と評価されている理由の大きなひとつです。
|GPTの歴史
GPTは初期モデルからアップデートを繰り返していることはご存知でしょうか?
GPTの初期段階は、AIに文章を生成させるために学習機能を搭載させ、自動で文章を構築することを目的に開発されました。
OpenAIは2018年に公開した「GPT-1」以降、年々パラメータ数が増え続け、2023年のGPT-4では非公開でありながらパラメータ数*は100兆以上ともいわれており、飛躍的な進化を遂げています。
*パラメータ数:モデルの複雑さや表現力を示す重要な要素で、パラメータ数が多いとモデルはより複雑なパターンや関係性を学習することができます
以下はGPTの歴史を図で表したものです。
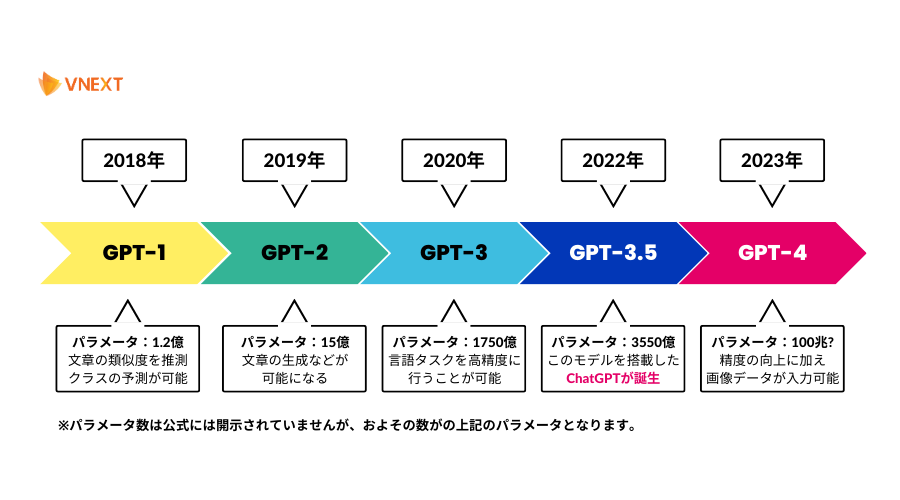
2023年3月15日に最新版「GPT-4」が公開されました。
GPT-4は、バリエーション豊富な質問や会話への回答の精度を向上させただけでなく、画像データの入力が可能となり、画像とテキストを交えた質問に対しても回答をしてくれるようになりました。
GPT-4に関しては、下記の記事で詳しく解説していますのであわせてご覧ください。
《関連記事》
【GPT-4とは】特徴やできること、GPT-3.5との違いを徹底解説!
このように、GPTは常に進化し続けており、今後どのような形になっていくのか楽しみでもあります。
|GPTの活用方法
GPTは、文章の生成から自動要約・翻訳、チャットボットの開発など、さまざまな分野で活用されています。ChatGPTがいい活用例ですね。
以下では、GPTの活用方法についてご紹介します。
・カスタマーサポート
GPTでは、疑問や悩みなどを質問すると自然な文章で返答してくれるので、カスタマーサポートの業務をAIチャットで対応することができます。
このようにサポートとしてGPTを活用することで、人件費や業務負担を軽減することができるため、業務改善を目的に導入する企業が増えています。
・予約業務
顧客からの予約対応でGPTを取り入れ、チャットボットとおしゃべりしてから予約したり、空き状況を聞いたり、予約内容の変更をお願いすることも可能です。
また、GPTは取得した情報からの推測が得意なので、顧客に合ったおすすめ商品や情報を提供するなど、最近では主に旅行業界で活用されています。
・企業のデータ分析を自動化
GPTは「言語理解・文章生成・AIによる返答・多国語翻訳」に対応いるため、企業のデータ分析も自動化することができ、業務の効率化やデータ管理の面でも使える用途の広いAIプラットフォームツールとしても活用できます。
たとえば、顧客分析を自動化・データから要約することができるので、データによる売上の予測をし、人では分析できない部分をサポートしてくれ、
今後の経営方針の参考にするなど企業のデータ分析ツールとして期待が高まっています。
・マーケティング
GPTの「文章生成・キーワード抽出・データ分析」機能を活用することで、マーケティング業務にかかる工数を減らすことが可能です。
大量のテキストデータからキーワードを抽出できるので、たとえば自社サイトのSEO対策のためのキーワード選定をし、そこからコンテンツのアイデア出し、文章作成までを短時間で行うことができます。
データ分析では、Webサイトのアクセスデータや顧客データからWebサイトの弱点を見つけ、どの施策を取り組めばいいのか提案をもらえるので、
これまで見つけられなかった潜在的な部分が明らかになったりと今後のマーケティング施策が打ちやすくなります。
|まとめ
ここまで、GPTの仕組みと歴史、GPTの活用方法をご紹介してきました。
GPTの「すごい」ところを3つにまとめると以下が挙げられます。
・汎用性が高く、なんでもできる(文章生成・質疑応答・要約・感情分析・データ分析など)
・文章の理解力と生成力の高さと言語理解からの予測や推測がより正確かつ自然
・従来のAI学習のプロセスをちゃぶ台返しするような画期的な学習方法
また、GPTは年々進化しており、性能やタスク処理の幅が広がってきています。
GPTは、自然言語処理タスクにおいて非常に効果的なモデルとなっており、ビジネスに活用することで業務効率化やDX支援にも貢献できるでしょう。
もしかしたら、現代のビジネスで欠かせないツールのような存在になる日も近いかもしれませんね。
実はこの記事の「GPTの学習方法」部分は、ChatGPTに質問し、返答されたものを記事用に修正を加え作成しています!
|VNEXTはGPTに関する開発にも対応
弊社VNEXTでも、GPTに関する開発実績があります!
弊社では日本でGPT-2が発表される前の段階で、日本語テキストをメインとするコーパス*を作成し、GPT-2に学習させ「ブログ記事・SEO記事の自動生成」を可能にしたアプリケーションをリリースしました。
*コーパス:大量のテキストデータを収集・整理したものであり、特定の言語やテーマに関する実際の文章の集合体のこと
GPT-3では、日本語に特化しコーパスを100%日本語で最初から学習させることで、文章の自然度をアップしただけでなく、「感情分析」と「Few-shot Learning*」も可能にしました。
*Few-shot Learning:機械学習の一種であり、限られたデータ(少数の例)で新しいクラスやタスクを学習する手法のこと
このように、オリジナルのエンジンを持っており、GPTを活用したソリューションを提供しています。
もちろん、ChatGPTを活用したシステム・アプリ開発も行っています!最近では「Voice Chat GPT」という”ChatGPT”と音声で会話ができるアプリのデモを開発しました。
このデモは、2023年6月14日から開催される「APPS JAPAN 2023」でご紹介いたします!
GPTを自社の業務に活用してみたいが何ができるかわからない方、GPTに興味がある方、AI開発を検討している方はお気軽にご相談ください!
VNEXTのAI開発についてもっと知る ▶️ こちら
|おすすめのAI資料
AI開発の流れから費用相場、開発コストを抑えるコツをご紹介している資料をご用意しました!
VNEXTのAI開発事例も掲載していますので、この機会にぜひ無料ダウンロードしてみてください。(下記バナーをクリック)


