

2024/06/24

AIは今や私たちの生活に欠かせない存在です。ビジネスから医療、自動運転まで、様々な分野で活躍しています。そのため、AIは企業にとって必要不可欠なものになりつつあります。
しかし、AIを上手に使うためには、その背景にある「機械学習」の理解が重要です。
本記事では、機械学習とは何か?種類と仕組み、AIやディープラーニングとの違いなどについて解説していきます。
目次
● 機械学習とは?● 機械学習の3つの学習方法▶︎ ① 教師あり学習▶︎ ② 教師なし学習▶︎ ③ 強化学習● 機械学習とAIやディープラーニングとの違い● 機械学習の仕組み● 機械学習の代表的なタスク● 機械学習の身近な活用事例● AI開発で使用されるプログラミング言語「Python」● まとめ |
|機械学習とは?
まずは、機械学習の意味や、機械学習でできること、AIやディープラーニングとの違いを確認しましょう。
|機械学習の意味
機械学習とは、AIにおける“学習”のこと。人間が学習するように「機械自身が学習する」という意味が込められています。
つまり、機械学習の目的とは、学習を経た機械が、プログラマーによってプログラミングされた範囲以上のことを実行できる状態にすることです。
機械学習は、機械が膨大な量のデータを学習することによって自らルールを学習し、そのルールに則った予測や判断を実現します。
「AI」や「ディープラーニング」と同時に語られることが多い言葉ですが、機械学習はAIを支える技術の1つであり、ディープラーニングは機械学習の手法の1つです。
機械学習の特徴は、膨大な情報を処理し、データの中から特徴や法則性を見出すこと。導き出された特徴・法則性に基づいて、物事の予測や判断が行えるようになります。
つまり、機械学習は、AIに学習能力を与えたり、大量かつ複雑なデータを持つビッグデータの処理や分析のために活用されています。
|機械学習が注目されている理由
2000年代以降は「第三次 AIブーム」とよばれ、近年もAIの活用は急速に広がり続けていますが、ブームの背景には、機械学習の実用化が進みAI自身が大量のデータから知識を獲得できるようになったことが影響しています。
さらに、2006年には知識を定義する要素(特徴量)をAIが自ら習得するディープラーニング(深層学習)が提唱され、ブームに拍車をかけました。
また、2022年以降、機械学習やディープラーニングの技術を用いて新しい画像を生成する「画像生成AI」や、人との自然なコミュニケーションや文章の自動生成、要約、情報収集などができる「ChatGPT」の登場により、専門的な知識を持っていなくても活用できるAIが世界中で急速に普及し始めています。
|機械学習の3つの学習方法
機械学習は大きく分けて、「教師あり学習」「教師なし学習」「強化学習」の3つに分類されます。それぞれを詳しくみていきましょう。
|① 教師あり学習
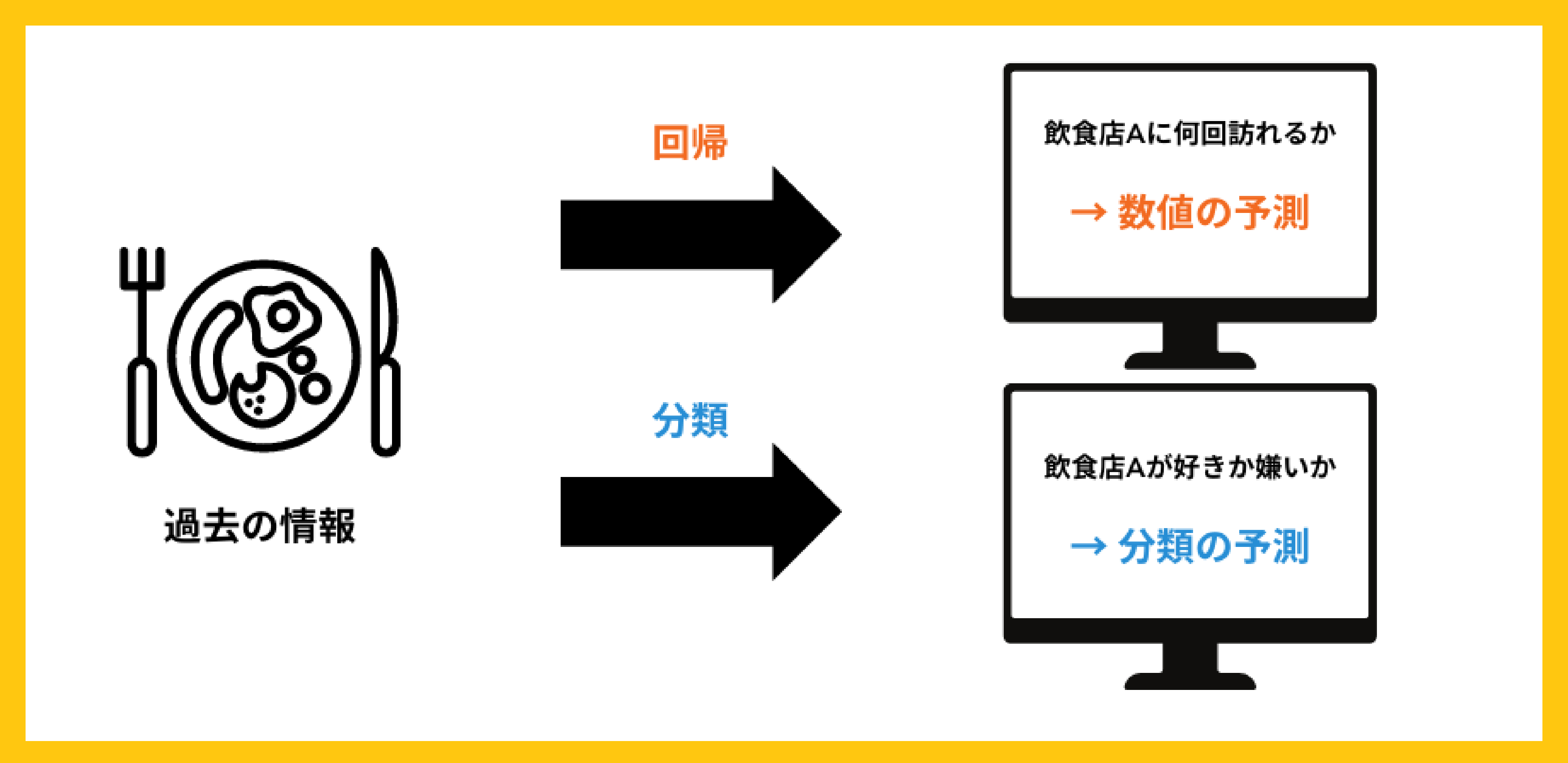
教師あり学習では、正解となるデータをあらかじめ読み込んだ上で、正解に紐づく結果を提示することが可能です。人間が予め付けていた正解ラベルに基づいて、機械が学習しデータセットに対する応答値の予測をするモデルを構築します。教師あり学習の代表的な活用事例として、「回帰」や「分類」が挙げられます。
回帰とは、「連続する数値の予測」のことです。たとえば、天候や平均気温といったデータとアイスクリームの販売個数の関係を学習することによって、「この平均気温であればこれくらいの売り上げが期待できる」といった予測を行うことが可能になります。
飲食店を例にした場合には、過去に訪問した飲食店の情報をもとに「新しい飲食店に何回訪れるか」を予測します。回帰の目的は「何回訪れるか」という具体的な値を予測することです。
一方の分類は、「あるデータがどのクラスに属するかの予測」を指すものです。たとえば、迷惑メールかどうかが判別されているクラス分けされたデータの中から、文章の特徴やクラスの関係を学習することによって、新着メールが迷惑メールかどうかを予測することが可能になります。
また、飲食店を例にすると、過去に訪問した飲食店の情報をもとに「新しい飲食店を気に入るかどうか」を予測します。分類の目的は「気に入るか、気に入らないか」というグループ分けを予測することです。
|② 教師なし学習
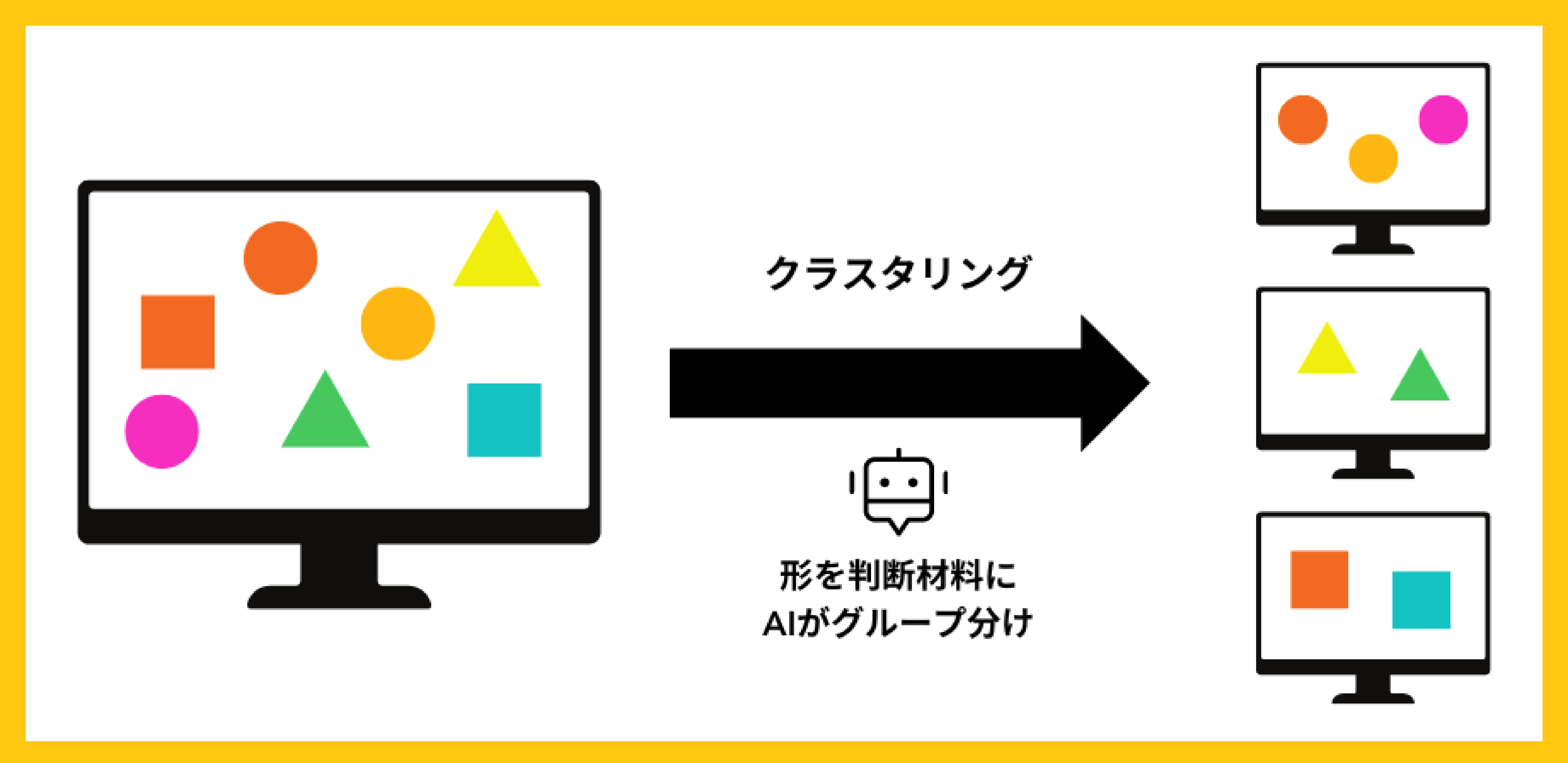
教師なし学習では、正解となるデータが存在しないため、入力されたデータを利用して基本構造や分布をモデル化していきます。一見、教師なし学習のほうが難しいように思えるかもしれませんが、適切な方法で学習を行えば、教師なし学習でも精度を高めていくことが可能です。
たとえば、「A」「B」「C」という性質を持つデータが無造作に配置されていた場合は、教師なし学習を活用することで「Aグループ」「Bグループ」「Cグループ」の3つグループに自動的に分けられます。教師なし学習は、答えを含まないデータを使用する代わりに、データ自身が持っているデータ内の構造を見分けるように作成されます。
|③ 強化学習
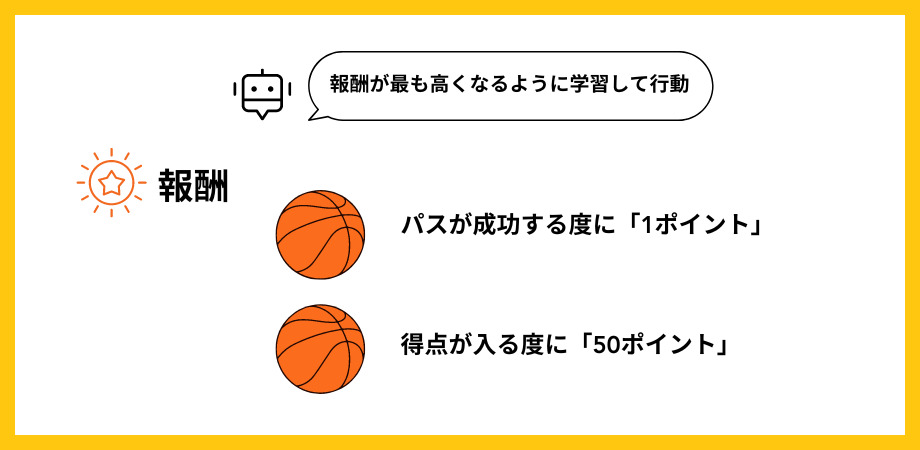
強化学習は、AIが自らの置かれた環境のなかで試行錯誤を繰り返し、最適な行動・価値を見つけ出す学習法で、報酬が最も高くなるように学習します。
バスケットボールのゲームを例にすると、パスが成功するたびに1ポイント、得点が入ると50ポイントといったアルゴリズムを搭載することで、自身で最適の方法を導いていくわけです。
最近大きな注目を集めている将棋AIには、この強化学習が活用されています。また、囲碁AIや掃除ロボットなども実際のシステムが使用されていて、強化学習は様々な分野で応用することが可能です。
|機械学習とAIやディープラーニングとの違い
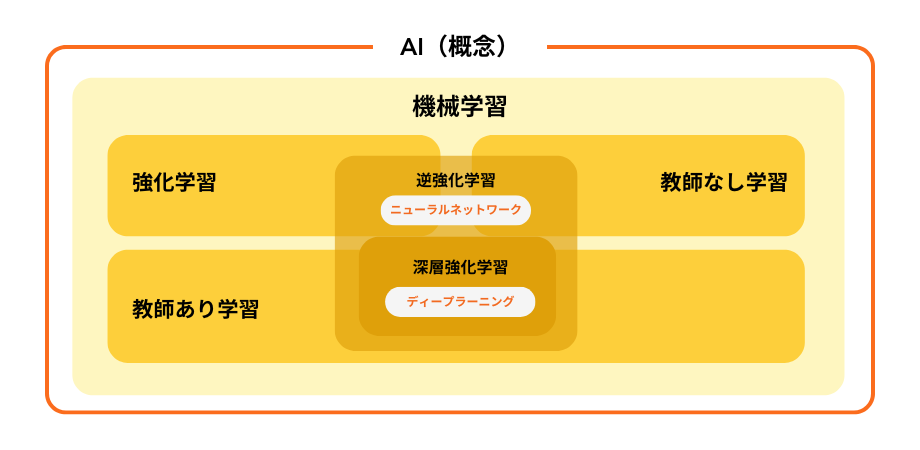
AIとは、「Artificial Intelligence」を略した言葉であり、日本語に訳すと「人工知能」となります。人間の脳で行っているような作業をコンピューターが同じように模倣し、自然言語を理解したり、論理的に推測したり、経験に基づく学習を行ったりすることを目的とするプログラムを「AI」と呼ぶのが一般的です。そして、AIが膨大な量のデータを学習し、予測・判断を行っていく技術を「機械学習」といいます。
また、ディープラーニングは、膨大な量のデータを学習し、共通点を自動で抽出していくことによって、状況に応じた柔軟な判断を下すことが可能になる「機械学習技術の内の1つ」を指します。従来の機械学習と異なる点としては、より高精度な分析を行うことができるという点が挙げられます。
《関連記事》
【ディープラーニングとは】基礎知識と仕組み、活用事例をわかりやすく解説!
|機械学習の仕組み
機械学習には、以下の4つのアルゴリズムが存在します。
◯ ニューラルネットワーク
◯ ニアレストネイバー法
◯ 決定木・ランダムフォレスト
◯ サポートベクターマシン
それぞれの仕組みについて解説していきます。
|ニューラルネットワーク
機械学習には多様なアルゴリズムが存在し、その内のひとつに「ニューラルネットワーク」というものが存在します。このニューラルネットワークとは、いわば「人間の脳神経の仕組み」のような機械学習アルゴリズムです。脳の回路に似た形のユニットで構成されており、「入力層」「中間層」「出力層」の3層で構成されています。そんな3層のうちの「中間層」を深くしたものがディープラーニング(深層学習)なのです。
この「中間層」を深くすることによって、ニューラルネットワークよりも表現力や精度を格段にアップさせることができます。つまり、ディープラーニング(深層学習)というのは、機械学習における3層のうちのひとつである「ニューラルネットワーク」をさらに発展させたものということです。
|ニアレストネイバー法
ニアレストネイバー法とは、クラスタリングに用いられる手法の1つです。
画像の拡大・縮小を行う際や、新しいデータに対して、最も近い既存のデータが属するクラスターに分類していく方式であるため、必ずしも高い精度を実現できるとは限りません。最近傍補間と呼ばれることもあります。
|決定木・ランダムフォレスト
決定木とは、分析されたデータをもとに自動的に樹形図を作成してくれることで、分析の解釈が簡単にできるのが特徴です。
処理の流れは、まずきれいにデータを分割する基準を決定します。次に、データ分割を行い、設定した基準になるまで「処理の流れ」「データ分割」を繰り返します。
また、ランダムフォレストとは、複数の決定木を使用して、「分類」または「回帰」をするアルゴリズムのことです。
|サポートベクターマシン(SVM)
サポートベクターマシンとは、2つのクラスのデータ群を分割するような境界線・超平面を決定することで、分類・回帰などの問題に適応可能な機械学習モデルの1つです。分類データにおいて非常に高い精度を誇る、マージン最大化という考え方を用いています。
マージン最大化は、2つのサポートベクトルから最も遠い位置に境界線を設定することを意味しており、サポートベクターマシンの肝になる手法です。マージン最大化によって、サポートベクターマシンは深層学習で使われるニューラルネットワークよりも少量データで、高い汎用性を出すことができます。
|機械学習の代表的なタスク
機械学習のタスクとは「問題・質問・利用可能なデータ」これらに基づいておこなわれる予測・推論の種類をいいます。機械学習の代表的なタスクは以下の8種類があります。
◯ 二項分類
◯ 多クラス分類
◯ 回帰
◯ クラスタリング
◯ 異常検知
◯ 画像分類
◯ 物体検出
◯ 予測
それぞれについて詳しくみていきましょう。
|二項分類
二項分類とは、属性によって2種類に分類することです。わかりやすい例としては、「奇数or偶数」「0 or 1」といったものが挙げられます。二項分類では、分類閾値(カットオフ)というものが判断材料に用いられます。閾値とデータを比較した結果をもとに、予測が行われる仕組みです。
なお、データ分類の代表的な方法としては、多項分類というものも存在します。その名前からもわかるように、属性に応じて3種類以上に分類する方法のことです。色による分類や、種類による分類などは、この多項分類に該当します。
|多クラス分類
多クラス分類とは、データを複数のクラスに分類する分析のことを指します。多クラス分類が活用されているサービスの一つに挙げられるのが、Yahoo知恵袋です。Yahoo!知恵袋では、Yahoo! JAPAN IDごとに知恵袋の閲覧履歴から、ディープニューラルネットワーク(DNN)を使用して、次に閲覧するアイテムを予測してレコメンドする仕組みが導入されています。
多クラス分類を活用することで、レコメンド候補に出す質問をある程度事前に絞り込んだ上で、候補の質問のスコアを一気に予測することが可能になっているのです。
|回帰
上述で解説したように、回帰とは「連続する数値の予測」のことを指します。たとえば、天候や平均気温といったデータとアイスクリームの販売個数の関係を学習することによって、「この平均気温であればこれくらいの売り上げが期待できる」といった予測を行うことが可能です。
|クラスタリング
クラスタリングは、「データ間の類似度に基づいてデータをグループ分けしていく手法」のことです。ただ、クラスタリングという単語自体は機械学習や統計学の以外でも用いられることがあるため、「クラスタ分析」や「データクラスタリング」といった呼ばれ方をすることも少なくありません。なお、クラスタリングによって分類されたグループは、クラスタと呼ばれます。
そんなクラスタリングの活用例としては、顧客の情報をクラスタリングすることによって「顧客のグループ分け(セグメンテーション)」を実行し、同じグループ内で同じ商品が複数回購入された場合には「同じグループに属する別の顧客にも同じ商品のレコメンドを行う」といった手法が挙げられます。
|異常検知
異常検知とは、大量のデータから通常とは異なるもの(異常)を検出することをいいます。
データマイニングを利用してデータセット中の他のデータと照らし合わせを行い、一致していないものを識別していくという仕組みです。そのため、異常検知における「異常」というのは、通常の動作として定義された概念に当てはまらないもののことを指しています。
そんな異常検知ですが、用途によっては「故障検知」「不正使用検知」といった呼ばれ方をすることもあります。そのため、これらを別物として捉えてしまう方もいらっしゃいますが、これらはすべて「他の大量のデータとは異なる振る舞いをみせるデータを検出する技術」であることに変わりはないため、すべて同じものと捉えて問題ありません。
なお、最近の異常検知では、以下のような「非構造化データ」が用いられるケースが多くなっています。
◯ メールや文章
◯ 動画
◯ 画像
◯ Webサイトのログなど
そのため、実際のビジネスにおいて活用していくためには、データ分析に関する知識や経験が必要になります。
|画像分類
画像分類とは、画像やデータを複数のグループに分類することです。
最近のスマートフォンでは、人物ごとに写真をグループ分けすることができる機能があるのをご存知でしょうか?これはまさに、AIの深層学習によって画像を分類しているということです。この機能を有効活用すれば、出荷前の商品に傷などがついていないか確認することもできます。
|物体検出
物体検出とは、取り込んだ画像の中から「物体の位置、種類、個数」を特定する技術のことを指します。物体の種類を分別すること自体は画像分類でも実現可能ですが、物体検出ではさらに「物体の位置の絞り込み」「対象外の物体の排除」を行うことで、対象物の位置・個数まで正しく検出することができます。
そんな物体検出は主に外観検査で活用されており、医療・建設業・製造業といったさまざまな分野で導入され始めています。最近ではスマートフォンのカメラでも利用できるケースが多くなっており、顔の検出などにも活用され始めている状況です。
また、近年注目を集めている自動車の自動運転においても、「歩行者を検出して事故を未然に防ぐ」という目的で活用されています。さまざまな分野で活用され始めているため、これからの時代において非常に重要な役割を担う技術といえます。
|予測
機械学習において最も重要なタスクと言っても過言ではないのが「予測」です。
過去のデータを蓄積することによって、高い精度での分析・予測を実現できるようになります。その一例としては、需要予測が挙げられます。
需要予測システムとは、蓄積されたデータの分析を行うことによって、在庫の最適化や収益の最大化などを実現するシステムのことです。一見、一連の作業すべてを自動化できる魅力的なシステムのように感じられるかもしれませんが、需要予測における一連の作業をすべて自動にできるというわけではありません。
より高い精度で需要予測を行うためには、「現状の業務把握」をヒアリングする必要があるからです。ただ、ヒアリングによって業務把握を行い、その上で「過去の実績」「天候による影響」といった要素を加えて需要予測モデルを構築していけば、より高い精度のシステムに仕上げることが可能になるのです。
そのため、最初に行われる「ヒアリング」という作業は、結果的に業務負担を大幅に軽減させる極めて重要なものであるといえます。また、適切なデータを活用し続けるためには、定期的なデータ検証・改善の作業も重要になります。
こういった作業を定期的に行うことで、在庫切れによる機会損失や在庫過剰による廃棄のリスクを軽減させることが可能になるため、結果的に収益の最大かにつなげることができるのです。
|機械学習の身近な活用事例
機械学習は、さまざまなシーンで積極的に活用され始めており、サービスの品質アップや業務効率化といった成果に繋げられています。わかりやすい身近な利用例としては、「画像認識技術による来店者情報の可視化」が挙げられます。
画像認識技術を活用したシステムは来店者の情報を可視化することができるという特徴があるため、防犯や本人認証といった目的に加え、マーケティングにも活用され始めています。
たとえば、AIが搭載されているカメラを店舗に搭載した場合、顔認証や画像認識の技術によって来店者のさまざまな情報を可視化することができるようになります。その一例としては、以下のような情報が挙げられます。
◯ 来店者の数
◯ 退店者の数
◯ 店舗前の交通状況
◯ ディスプレイを閲覧した人の数
◯ 店舗内の混雑状況
◯ 店舗の平均滞在時間
◯ 来店者の属性(性別、年齢など)
◯ 新規客の数
◯ リピーター客の数
◯ 商品の購買率
主にこれらの情報を可視化することが可能になるため、防犯という観点だけでなく、より売上を向上させるためのマーケティングとして活用していくことができるわけです。これは、AI搭載のカメラによって機械学習が行われているからこそ実現できる大きなメリットといえます。
|AI開発で使用されるプログラミング言語「Python」
AI開発で使用するプログラミング言語の定番といえば「Python(パイソン)」です。
数あるプログラミング言語のなかでもコードが扱いやすく、機械学習に必要なビッグデータの処理に適しているという点が大きな理由といえます。さらに、もともと科学技術計算を実行しやすいうえに、機械学習向けのライブラリが揃っていることから重宝されています。
他の言語に比べてプログラミング初心者でも学びやすいということもあり、AIブームも相まって注目を集めています。
|まとめ
機械学習とは、機械に学習させ、膨大なデータから特徴や法則を見つけさせることです。AIに内包される技術の1つであり、さまざまなサービスやプロダクトに活用されています。
AIは、機械学習を用いて膨大なデータを学習し、法則を見出すことで、単純作業の効率化や、人為的なミスの削減に効果を発揮します。
機械学習には、教師あり学習と教師なし学習、強化学習の3つの種類があり、これらは二項分類やクラス分類、回帰などのタスクを行うことが可能です。機械学習を上手く活用して、サービスの品質向上や業務効率化を図りましょう。
|AIの導入をご検討中の経営者様・企業担当者様へ
弊社VNEXTでは、AI研究・開発に特化したチームを組んでおり、AIを用いた豊富なプロダクト開発実績があります。開発経験・知見・ノウハウが豊富なAI専門家がヒアリングでお客様のニーズを引き出し、コンサルティングをすることで、お客様に最適なAIソリューションを提供します。
AIの導入をご検討されている方は、一度VNEXTにご相談ください!
>> VNEXTのAI開発サービスの詳細はこちら
|【無料ダウンロード】AI開発の流れと費用、開発コストを削減するコツ
AI開発を検討するうえで、
「AIはどのような流れで開発していくのか?」
「費用はどのくらいかかるのか?」
「開発コストを削減する方法はあるのか?」
といったお声を多く頂きます。そんなお声にお応えする資料をご用意いたしました!
下記バナーより無料でダウンロードできますので、この機会にこの資料を参考にしてみてください。
