

2024/06/19

私たちが日頃使う言葉である自然言語には、意味を複数に解釈できる「曖昧さ」が含まれています。
自然言語処理(NLP)とは、コンピュータが、私たちが使う日常の言葉の解釈を1つに絞りながら、できるだけ自然に意味を把握するための技術です。
この技術を応用することで、「機械翻訳」や、大量のテキストデータを処理して有益な情報のみを取得する「テキストマイニング」へとつながります。
本記事では、自然言語処理(NLP)の意味や仕組み、活用事例についてわかりやすく解説していきます。
目次
|自然言語処理(NLP)とは?
自然言語とは日常的に私たちが使う話し言葉や書き言葉です。人々がコミュニケーションを取るために文化的背景のなかで自然に発展してきた言語であるため、このように呼ばれています。人為的に作られた「人工言語」や「プログラミング言語」が対義語となります。自然言語について詳しく見ていきましょう。
|自然言語の定義
自然言語処理(NLP:Natural Language Processing)とは、日常的に人が使う言葉を、コンピュータが正しく解析し、処理するための技術です。自然言語処理の技術は、コンピュータに話しかけると異なる言語に翻訳してくれる翻訳技術や、企業にある大量のテキストデータを高速・正確に処理するAI技術などにつながっていきます。しかしながら、未だ完璧な自然言語処理は実現できているとは言えません。
なぜ未だに自然な翻訳が実現できていないのでしょうか? それは、自然言語が持つ曖昧さが要因となっているのです。
話し言葉からの自然言語処理を行う場合、一般的にはコンピュータが音声をテキスト化し、テキストを品詞分解、意味を解釈する、という流れで行われます。
|具体例で理解を深める
たとえば、下記の例文の話し言葉をコンピュータで処理することを考えてみましょう。
「いぬがねこをうんだよ」
この文は主に、
|
① 犬が猫を産んだよ ② 犬が子を産んだよ |
の2つの解釈に分けることができます。
我々人間であれば「犬が猫を産むわけがない」と考えるので、①は消去され、②を選びますが、機械はどちらを選ぶべきかわからなくなってしまいます。
このような、複数に解釈できる可能性があることを「曖昧さ」といいます。自然言語では人工言語とは異なり、曖昧さを持つ文章が存在しているのです。
コンピュータが曖昧さを持つ文を一つの意味に解釈し、正しく認識するには、単語の持つ意味や、文脈から判断するための学習が必要です。近年、ディープラーニングの登場により、コンピュータの解釈の精度は劇的に向上しています。
|自然言語処理(NLP)が注目を集める理由
近年話題のChatGPTも自然言語処理によって対話を実現していますが、自然言語処理が注目されている理由は主に3つ挙げられます。
近年では、SNSやビジネスコミュニケーションツールの発達によりテキストデータを収集しやすくなっています。
社内でのコミュニケーションツールとして、SlackやChatworkなどを導入するケースが増え、従来は紙でのやり取りだったものがデジタルデータに置き換わりました。また、議事録の生成ツールによる資料のデータ化、紙媒体の電子化が増加しており、今後はさらにテキストデータ量が増えることが予測されています。
ペーパーロジック社の調査では、東京都内の企業のうち75.7%が社内のペーパーレス化を推進し、そのうちの60.7%が2021年度にペーパーレス化推進システム導入の予定/検討していると回答しています。
こうした背景から書類のPDF化率が極めて高くなっており、今後テキストデータの活用がさらに進むことが予想されます。
|GPT-3やBERTなどの汎用言語モデルが進化
2つ目の理由は、言語処理研究開発において汎用言語モデルの研究が進み、技術革新が進んでいることです。
自然言語処理(NLP)の分野では、一般的に単語や文の単位で入力を処理します。 最近よく用いられているのは、一般的な文章に対して単語や文を処理する汎用的なモデルを用意し、このモデルを各タスクに合わせてチューニングする方法です。 この汎用モデルを「言語モデル」と呼んでいます。
2018年にGoogleが発表した汎用言語モデル「BERT」は、さまざまな自然言語処理タスクで当時最高のスコアを叩き出しました。2019年には、イーロン・マスク氏らが投資しているAI研究機関のOpenAIが、自然な文章を生成する言語モデル「GPT-2」を発表し、そして2020年には、OpenAIが「GPT-3」を発表しました。人間並みに自然な文章の生成を実現し、その精度の高さから世界中の注目を集めています。
同年の9月22日には、Microsoft社がOpenAIとGPT-3に関する独占的ライセンス契約を行ったと発表しています。
これらの影響を受け、日本語における自然言語処理技術も発展の兆しを見せています。
2020年11月、LINE株式会社はNAVERと共同で世界初となる日本語に特化した超巨大な言語モデルを開発することを発表しました。2022年1月時点で390億の日本語モデルの構築に成功しており、2022年度中に2040億パラメータのモデルの構築を目指していると述べています。
この開発により、日本語での自然言語処理技術の水準が大きく飛躍するといわれています。
また、2022年3月には東京大学松尾研究所発のAIスタートアップである株式会社ELYZAが文章執筆AIのデモサイト「ELYZA Pencil」を公開しました。キーワードから文章を生成できる日本語AIの一般公開は国内初となります。
このように、汎用言語モデルの研究が進み、高度な言語処理が可能になりました。また、英語のみならず、日本語における自然言語処理(NLP)の技術も大きく向上していくことが予測されます。
|市場規模の高まりやDXの実現
自然言語処理技術は近年ますます発展しており、ビジネスでの応用事例も増えています。そして現在導入が推進されているDXの実現にも欠かせないものとなっています。
人員や時間などが限られたリソースの中で成果を出すためには、自動化ツールやAI技術が不可欠です。
たとえば、自動言語処理を応用することで、既存顧客とのやりとりで発生するテキストデータを元に、顧客の関心度の高いキーワードリストを自動生成し、自社のSEO対策に役立てられます。そしてそれが新たな施策の立案や改善へとつながります。
こうした流れから、自然言語処理(NLP)の需要が高まっていることがわかります。
|自然言語処理(NLP)でできること
日常的に私たちが使う言葉をコンピュータが処理できると、どのようなことが実現できるでしょうか。実際に使われている身近な例を含めて紹介します。
|機械翻訳
「機械翻訳」は、自然言語処理でできることの代表例です。外国語と日本語との機械翻訳では、特にGoogle翻訳が有名です。使ったことがある方もいるのではないでしょうか?
近年、ドイツのDeepL SE社が開発した「DeepL」は、より自然な文脈で正確に翻訳が行われるとのことで人気が出ています。また機械翻訳には、カメラで直接テキストをスキャンして翻訳する「カメラ翻訳」や、端末のマイクに話した音声が自動で翻訳される「音声認識翻訳」といったものも存在しています。
|音声対話システム・チャットボット
ユーザーの音声での質問に対し自然言語処理を行い、質問に対する回答を音声データに変換して答える「音声対話システム」も身近な例です。iPhoneに搭載されている「Siri」やAndroid端末に搭載されている「Google アシスタント」がその代表です。
また、企業のホームページなどにおいて、ユーザーが打ち込んだ質問に、文章の文脈や意味合いを的確に理解した上で、最適な回答を文章化してくれる「チャットボット」も近年よく利用されています。
|予測変換機能
コンピュータや携帯電話で単語の始めの数文字を打つと、候補を表示してくれる「予測変換機能」があります。文字入力を削減してくれるこの機能は、特に携帯電話だと便利さを感じている方もいるのではないでしょうか。
予測変換の方法としては、入力履歴を参照した候補表示や、内部の辞書を参考にした表示、中には辞書をもとに文脈を判断した予測表示をするものもあります。これらの候補表示には自然言語処理技術が応用されています。
|テキストマイニング
「テキストマイニング」とは、大量のテキストデータから有益な情報を取り出すことです。テキストデータを分類し、文脈や意図を解析することで、知見であるインサイトの発見へとつながります。
たとえば、コールセンターでは顧客の対応記録が蓄積されており、このデータには、不満やニーズなどの有益な情報が含まれています。この大量のデータをコンピュータに解析させ、有益な情報を取り出したい場合、「どんなお客様が、いつ、どのような内容を話していたか」を分類した上で、有益と思われる情報を取り出さなくてはなりません。
この処理に使われるのが、自然言語処理です。自然言語処理を用いてテキストマイニングを進めることで、有益な情報のみを抽出し、企業のサービスに役立てることができます。
|自然言語処理(NLP)の仕組み
自然言語処理の仕組みを具体的に見ていきましょう。
ここでは、自然言語処理をジグソーパズルにたとえて説明していきます。
人間の作ったジグソーパズルを遊んでいるロボットがいて、目の前にジグソーパズル、隣には完成系の絵が置いてある場面を想像してみてください。
自然言語処理は、最終目標である「絵(文章)」を完成させるために、
|
・形態素解析:各パズルの色や構造情報を表す ・構文解析:各パズルの凹凸を確認してつなぎ合わせる ・意味解析:ひとかたまりのパズル群が全体のどこにいるのか確認する ・文脈解析:最終調整を行う |
などの行程を経てジグソーパズルを組み立てていくものだと仮定します。
各段階を行う上で必要となるのが機械可読目録とコーパスです。まずこの2つについて説明してから、自然言語処理の流れを解説していきます。
|機械可読目録
機械可読目録(MARC, MAchine-Readable Catalog)とは、書き言葉の書籍情報や関連情報を機械が読める形に置き換えた通信規格です。言い換えると、ロボットの目であり、文字を認識することそのものです。1960年に開発され、応用技術のひとつに図書館などの書籍検索システム「OPAC」があります。俗に自然言語処理用の「辞書」と定義され、ここで文字を機械が読み取れる規格に変換します。
|コーパス
コーパス(Corpus)とは、自然言語の文章などの使用方法を構造化して大規模に集め、記録したものです。言い換えると、ロボットの頭脳であり、パズルの形状(構造)や色(品詞)を確認するものです。構造化した後、言語情報(動詞、形容詞などの品詞・統語構造)などのタグ付けをします。日本語では「言語全集」などと言われることもあります。
コーパスは、この後解説する解析時に利用します。
そしてここから、自然言語処理は主に4つの行程を踏まえて処理されます。
● Step1:形態素解析
● Step2:構文解析
● Step3:意味解析
● Step4:文脈解析
段階ごとに詳しく説明していきます。
|Step1:形態素解析
まずは出来上がっているジグソーパズルをバラバラにしていきます。
形態素解析とは、文章をそれぞれの意味を担う最小の単位(=形態素)に分割し、それぞれに品詞など各種情報を振り分ける作業です。大小感覚は、文>単語>形態素という具合です。パズルゲームに置き換えると、各パズルの色や構造情報を表します。
これにより、文章のなかにある形態素の意味をデータとして抽出することが可能になります。
具体例として次の文を形態素解析してみましょう。
「私は同僚と美味しいランチを食べました」
これを形態素解析すると以下のようになります。
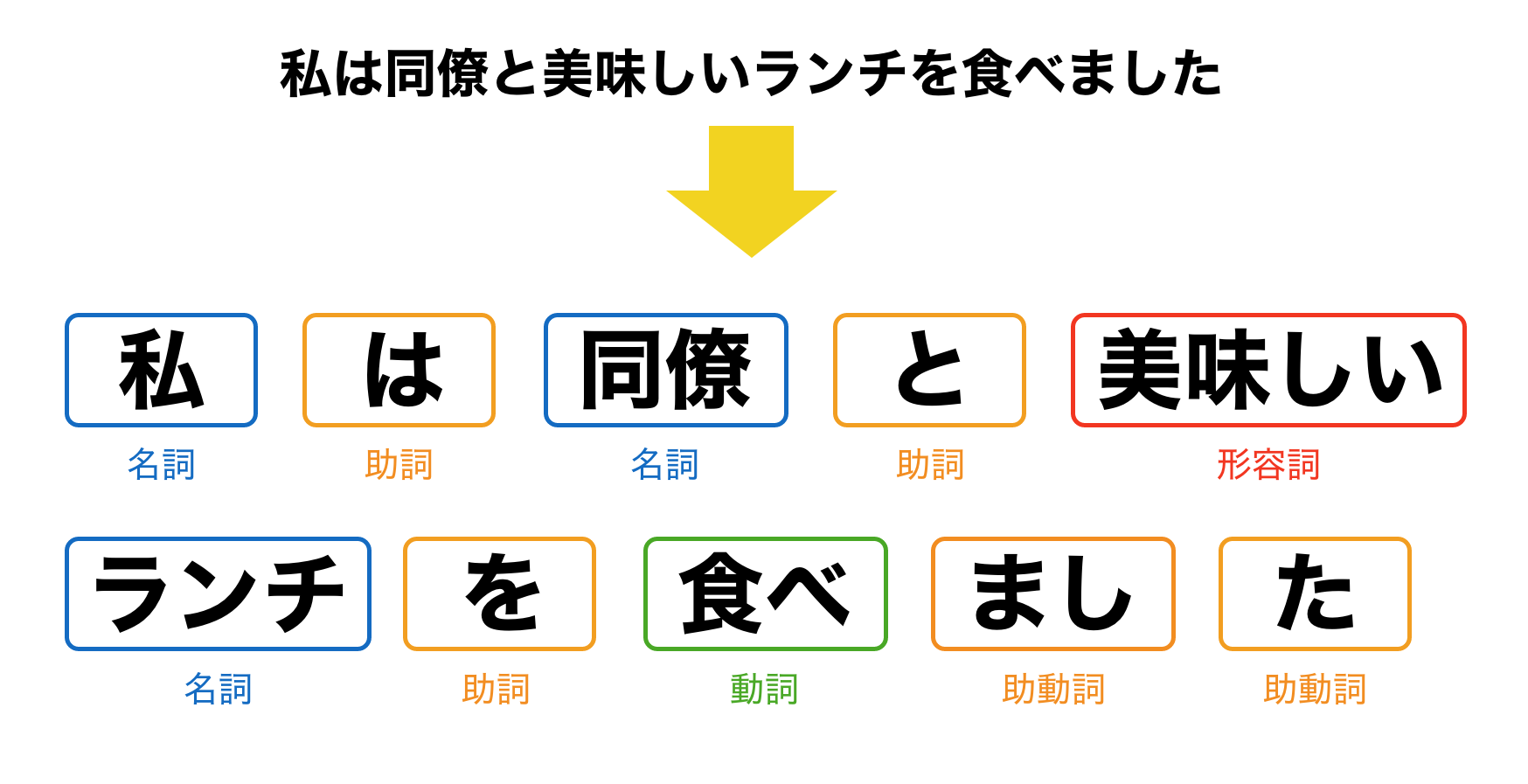
テキストのみでは、コンピュータには名詞や動詞がどれか、といった情報がすぐにはわかりません。そこで、テキストを「形態素」と呼ばれる意味を持つ最小単位に分け、品詞を解析していきます。
「私(名詞)は(助詞)同僚(名詞)と(助詞)美味しい(形容詞)ランチ(名詞)を(助詞)食べ(動詞)まし(助動詞)た(助動詞)」
このように文章を分割して書くことを「分かち書き」と言います。
|Step2:構文解析
次にそれぞれのパズルがどのパズルと隣り合わせになっているか確認します。
分かち書きされた文章から、どこまでが名詞句で、どこが述語なのか、などの判断し、単語同士の関係性を解析していきます。
形態素解析で得た、分かち書きの文を解析すると、例として以下のような構造が考えられます。
「私は(名詞句)」「同僚と美味しいランチを(名詞句)」「食べました(述語)」
「私は(名詞句)」「美味しいランチを(名詞句)」「同僚と(名詞句)」「食べました(述語)」
このように、取りうる構造をすべて列挙していきます。
|Step3:意味解析
構文解析までの手順で、ひとかたまりのパズルがいくつか出来上がりました。しかし、それらが本来どの場所に配置されているか判断できないと、パズルは完成しません。
そこで、パズルが完成形のなかでどの位置にいるのかを調べていきます。
意味解析とは、「辞書」に基づいた意味を利用して正しい文を解析することです。
冒頭で取り上げた、「いぬがねこをうんだ」という文が曖昧さを含んでいるように、意味の取り方によって文の解釈が変わってきます。
今までの解析同様、意味解析にも多くの解析方法があります。中でも「グラウンディング」という概念は、事前に用意してあるリストから文章中の固有名を結びつけてその意味を認識します。最終的に正しい解釈に解析することがここで行われます。
例文には、以下2つの解釈があります。
|
・私は、同僚と美味しいランチを食べました(私が、同僚とランチ両方食べた場合) ・私は同僚と、美味しいランチを食べました(私と同僚で、ランチを食べた場合) |
ここでロボット(機械)は「辞書」を頼りに正しい解釈を探します。
|
・「私」と「同僚」は関係性が高い(同じ名詞、人間の名称) ・「同僚」と「美味しい」は関係性が低い(名詞と形容詞、適切ではない形容詞) ・「美味しい」と「ランチ」は関係性が高い(ランチは食事の名詞、美味しいは形容詞) |
そしてようやく、「私は同僚と、美味しいランチを食べました」が正しい解釈だと解析します。
|Step4:文脈解析
最後にひとかたまりのパズル同士を組み合わせて絵(文章)を完成させます。
文脈解析とは、複数の文章に形態素解析と意味解析を行い、文同士の関係性を解析することです。
しかし、この行程は単純に文が長くなるだけではなく、お互いの関係性を正しく解析しなければなりません。なので、今まで利用していた「辞書」や「コーパス」の領域を超えて、さまざまな領域の「知識」を機械に学習させる必要があります。ここで「機械学習」と「ニューラルネットワーク」も絡んできます。この複雑さが課題となり、いまだ実用的な文脈解析システムができていないのが現状です。
しかし現在は、談話解析と呼ばれる方法論の研究が進められています。なかでも照応解析は代名詞や指示詞などの指示対象を推定したり、省略された名詞句を補完し処理をしたりする解析で、日本語の自然言語処理になくてはならない解析方法の1つとされています。
最終的に例文以外の文にも同じ手順を行い、文脈解析を行います。
結果、以下のような文章が機械に認識されます。
「今日の昼、私は同僚と、美味しいランチを食べました。食べ過ぎたのか、午後は少しうたた寝をしてしまいました」
形態素解析、構文解析、意味解析、文脈解析4つの手順を踏まえて、自然言語は機械言語へ変換され、データとして利用することが可能になります。
仕組みは長く複雑ですが、コンピュータの性能が向上した現代ではさまざまなライブラリを通して効率よくデータ化できます。Pythonなどのプログラミング言語の人気も相まって、さらなる活用が注目されています。
|自然言語処理(NLP)の活用事例
自然言語処理(NLP)を用いたサービスは現在多くの場所で提供されていますが、普段よりパソコンやスマートフォンを何気なく利用しているとあまり意識する機会がないかもしれません。
そこでこの項では、自然言語処理を活用した5つの事例を紹介していきたます。
|対話型AIチャットボット
チャットボットと呼ばれる対話システムは、自然言語処理を用いたサービスの1つです。自分が入力した文の文脈や意味を的確に理解して最適な回答を文章化する際に、自然言語処理が用いられています。
日本語では、主語が抜けただけで意味が大きく変わることがあります。そのため、チャットボットでは直前の会話に出てきた主語を記録してその後のコミュニケーションに活かすなどの仕組みがあります。
|音声認識AI
音声認識AIの多くが、自然言語処理と組み合わせて運用されています。
たとえば、近年注目されているサービスとして、音声認識による議事録作成があります。議事録作成では、音声認識によって言語として認識された音素をテキスト化します。この人が発する言葉をテキストにして残す技術に自然言語処理が役立っています。会議で音声認識AIを用いれば、会議の終了と同時に議事録が完成します。
またAIが学習を重ねれば、業界用語や会社特有の独特な単語や言い回しなども聞き取れるようになっています。
|AI-OCR
AI-OCRの精度の向上にも、自然言語処理が役立てられています。AI-OCRとは、手書きなどの文字をカメラが認識し、文字データへと変換する技術です。
紙媒体のデータ化は、業務効率化を目指す多くの企業で課題となっています。紙媒体のデータを電子化したり、申込書などに記載された内容をデータ化したりできると、事務手続きなどをスピーディーに進められます。
《関連記事》
【AI-OCRとは】OCRとの違いや種類・特徴、メリット・選定ポイントを解説!
|スマートスピーカー
スマートスピーカーは、対話型AIチャットボットの音声版と捉えることができます。自然言語処理は自然言語をコンピューターが理解して文章を生成するものですが、音声認識技術と組み合わせることで音声による言語認識まで実現できます。
スマートスピーカーは単に音声による会話を実現するだけでなく、電気をつける・鍵を閉めるなどの特定のタスクを実行するためにも用いることが可能です。
Amazonのスマートスピーカー「Alexa」やAppleの「Siri」、Google の「Googleアシスタント」などで広く知られる対話システムも、自然言語処理によるものです。
|検索エンジン
自然言語処理の代表例として挙げられるのが、検索エンジンです。
自然言語処理(NLP)、機械学習などのAI技術を活用すると、自然文で入力された検索文が保存されたドキュメントとは完全に一致しない場合でも、膨大なデータの中から目的とするドキュメントを検索できるようになります。
これによって、記憶の奥にあるあいまいなイメージやキーワードを元に、膨大なデータの中から目的のデータを探し当てられる可能性が高まります。
|まとめ
自然言語処理(NLP)は、コンピュータが自然に人間のように言葉を把握できるようになるための技術であり、音声認識や翻訳、テキスト情報の解析に活用されています。ディープラーニングを活用した自然言語処理により、形態素解析と構造解析の精度は一層高くなりました。
自然言語処理を活用することでコンピュータが可能な業務を増やすことで、より有益な業務に集中することができるようになります。少子高齢化により労働人口の減少が始まっている日本において重要な課題です。現状の技術を踏まえ、業務で取り入れられることはないかを検討していきましょう。
|自然言語処理の活用を検討している企業ご担当者様へ
弊社VNEXTでは、自然言語処理(NLP)を活用したシステムやアプリの開発実績が多数あります。
この記事で、自社のシステム・アプリに自然言語処理を活用してみたい、自然言語処理に興味を持った、という方はぜひお気軽にVNEXTにお問い合わせください!
>> VNEXTのAI研究・開発支援サービスの詳細はこちら